
Az MI szerepe a programozásban
A mesterséges intelligencia egyre nagyobb szerepet játszik a szoftverfejlesztésben. Pár éve bizonyos nagyon mechanikus munkákat lehetett rábízni, pár hónapja junior fejlesztőként tekintettünk rá, jelenlegi (2026 eleje) viszont a szerepét a következőképpen lehet jól megfogni: egy mindent tudó félautonóm társfejlesztő. Bontsuk ki az egyes részeket:
- Mindent tudó: minden olyan programozási nyelvvel, keretrendszerrel, könyvtárral, technológiával kapcsolatban tud segíteni, amivel egy szoftverfejlesztő kapcsolatba kerülhet. Emiatt a tulajdonsága miatt már több mint junior fejlesztőként tekintünk rá, mivel a junior fejlesztő tipikusan egy-két nyelvet és egy-két további technológiát ismer. A mindentudás az általános tudásra vonatkozik, a céges belső tudásokra még nem (vagy csak korlátozottan), tehát itt lexikális ill. technológiai mindentudásról beszélünk.
- Félautonóm: ez két dolgot is jelent, a nullához képest is és a 100%-hoz képest is félautonóm. A teljes autonómiához képest azt jelenti, hogy magától nem fejleszt szoftvert, azt meg kell neki mondani. Időnként félbehagyja vagy rossz irányba megy, tehát “noszogatni”, tovább lendíteni, terelgetni kell. A nullához képest is félautonóm, ugyanis már bőven több, mint az “egy feladat → egy megoldás” modell. A feladatokat részekre bontja, külön-külön megoldja, ha hibára fut, visszalép stb.
- Társfejlesztő: nem lecseréli, hanem segíti a fejlesztőt. A “mester” továbbra is az ember. Az ember irányítja a mesterséges intelligenciát. Az ember hagyja jóvá a változtatásokat, az eredmény az ember szellemi terméke (még akkor is, ha 100%-ban a gép generálta), és egyúttal minden felelősség az emberé. Tehát az eredmény olyan (elismerés és felelősség szempontjából is), mintha az ember készítette volna.
Az MI tehát egy eszköz a szoftverfejlesztő kezében, ahogy mondjuk egy integrált fejlesztőkörnyezet is az, ami egyszerűbbé és hatékonyabbá teszi a munkát. Se több, se kevesebb. Jelenleg egyáltalán nem teszi feleslegessé a szoftverfejlesztő munkáját. A hatékonyságot viszont növeli, tehát ha az elvégzendő munkamennyiség nem változik, akkor kevesebb fejlesztőre van szükség. Ilyen közvetett hatása van a munkaerőpiacra, de olyan közvetlen nincs (és a közeljövőben nem is várható), hogy robotként beül a fejlesztő helyére, átvéve annak a munkáját.
MI eszközök a szoftverfejlesztésben
Klasszikus chatbotok
A chatbotok szinte mindegyike alkalmas kódolási feladatok elvégzésére, és a fejlődés szédítő: az egy évvel ezelőtti, kifejezetten kódolásra tanított modellek messze elmaradnak a mai, mondjuk elsősorban versírásra tanított modellekkel szemben, amelyek mellesleg programozni is tudnak. Tehát használhatjuk a kedvenc chatbotunk akár ingyenes változatát, megkérhetjük, hogy programozzon le egy-egy egyszerűbb feladatot, és jó esélyünk van arra, hogy megcsinálja.
Ismertebb példák:
- ChatGPT (OpenAI): https://chatgpt.com/
- Gemini (Google): https://gemini.google.com/
- Claude (Anthropic): https://claude.ai/
- DeepSeek: https://chat.deepseek.com/
- Perplexity: https://www.perplexity.ai/
Lehetőségek: a hosszabb kódoláson kívül szinte bármit meg tudunk vele csináltatni.
Korlátok: nem látja a kódbázist, valamint a lokális futtatási lehetősége korlátozott. Ezáltal a legenerált kódot át kell másolni egy szerkesztőbe és kívül lefuttatni. Sokszor hibás kódot generál. Mivel nem látja a kódbázist, a releváns kódot egyesével kell feltölteni. A chat ablakban korlátozott mennyiséget lehet feltölteni, a fájlfeltöltést pedig az ingyenes változatok erősen korlátozzák.
A tapasztalat szerint számos esetben több irányba indul el. Ezek közül némelyik hibás, és a javítást is több irányba indítja. Ezáltal szinte minden egyes lépésben több lesz a nyitott útvonal, mint korábban. Néhány iterációt után már olyan sok irány van, amit nehéz átlátni. Komolyabb feladatok esetén érdemes más módszert választani.
Saját gépen futtatott chatbotok
Ez annyiban tér el az előzőtől, hogy a chatbot nem egy böngészőablakban, hanem egy, a számítógépen futó alkalmazásban fut. Látszólag nincs nagy különbség, ám a mélyén van egy lehetőség, ami drasztikusan kitágítja a lehetőségeket, ez pedig az ún. MCP.
Az MCP a Model Context Protocol rövidítése, ami egy MI-vel kapcsolatos szabvány. A lényege az, hogy bizonyos kérdések esetén lokálisan lefuttasson bizonyos (Python) függvényeket. 3 példa ezekre a függvényekre:
- “Ha a felhasználó egy adott könyvtár tartalmát kéri, akkor futtasd le ezt a függvényt”, ami egyébként visszaadja az adott könyvtár tartalmát.
- “Ha a felhasználó egy adott fájl tartalmát kéri, akkor futtasd le ezt a függvényt”, ami egyébként beolvassa és visszaadja a fájl tartalmát.
- “Ha a felhasználó egy adott fájlba szeretne írni, akkor futtasd le ezt a függvényt”, ami a fájlba írja a kért tartalmat.
Ezzel gyakorlatilag teljes hozzáférést adtunk a fájlrendszerhez. És további lehetőségeket adhatunk, pl. egy adott parancs végrehajtása, adatbázis írás-olvasás stb. Ezzel tehát elkerülhetjük a sok copy-paste műveletet.
A módszer korlátai: programozói tudás kell hozzá (Python programozási nyelv és a fastmcp könyvtár ismerete), ill. ez valójában a lehetőségek meghekkelése. A valódi fájlrendszerhez történő hozzáférést a következő módszerekkel érdemes alkalmazni.
Példák:
- Claude AI: https://claude.com/download
- ChatGPT: https://chatgpt.com/download
IDE beépülők
Az integrált fejlesztőkörnyezetekben az első MI segédek az intelligens kódkiegészítők voltak. Ezeket megelőzően is létezett kódkiegészítés, de az abban merült ki, hogy használat oldalon ajánlatot adott pl. változó- vagy függvénynévre, magyarán, ha egy hosszabb változónév első néhány betűjét beírtuk, akkor lehetőséget biztosított a lehetséges befejezésekre.
Az MI kódkiegészítés több ennél: ez figyelembe veszi a tágabb kontextust, megpróbálja kitalálni a fejlesztő tágabb értelembe vett szándékát, és akár több soros javaslatot ad.
Például az alábbi esetben egy py kiterjesztésű (tehát Python forráskódban) annyit írtam be, hogy def is_prime, ami a Pythonban egy függvény létrehozását jelenti, és a GitHub Copilot a következő javaslatot adta:
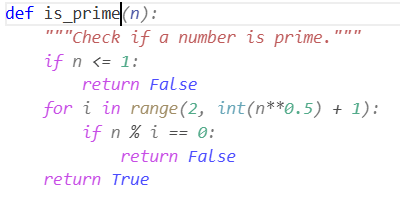
Tehát feltételezte, hogy egy egyszerű prímellenőrző függvényt szeretnék írni, és adott egy komplett megoldást.
Majd annyit írtam be, hogy for, ebből arra következtetett, hogy le szeretném tesztelni, és ezt tipikusan 20-ig érdemes, mert az még nem annyira sok, hogy ne lehessen átlátni, de már van elég sok prím és elég sok nem prím, ráadásul különböző okok miatt (pl. négyzetszám prímszerese), és az alábbi javaslatot adta (ezen a ponton csak annyi van beírva, hogy for)
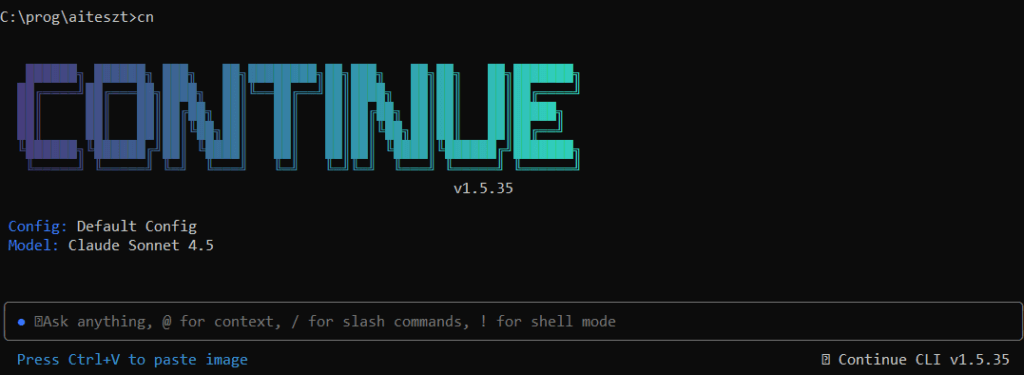
Az MI viszont már messze többet tud, mint az intelligens kódkiegészítés. Van chat ablak, tehát mindazt tudja, mint a chatbot. Viszont minden trükközés nélkül hozzáfér a kódbázishoz, így nem kell másolni és beilleszteni a kódot, megcsinálja magától. Nem kell feltölteni a kód többi részét, mert ott van, látja. Mivel az integrált fejlesztőkörnyezeteknek van terminál ablakuk, amihez az MI hozzáfér, tud parancsokat futtatni, és tudja magát a programot is. Tehát pl. egy olyan utasítást kiadhatunk neki, hogy “futtasd le az egységteszteket és javítsd ki a talált hibákat”.
További lehetőségek: bizonyos konstrukciók (ld. később) esetén “látnak”: tudnak képet generálni, amit “meg tudnak nézni”, valamint tudnak böngészőt indítani, így azt is “meg tudják nézni”, hogy milyen az eredmény. Egy webalkalmazásnál pusztán a HTML felépítéséből (DOM) nem biztos, hogy rájönnek arra, hogy egy rosszul beállított CSS miatt egymásra csúsznak a nyomógombok, de a böngészőben ezt észreveszi.
A használatához többféle módszer is létezik:
- Az MI segítő feltelepítése kiegészítőként. Például a Visual Studio Code a feltelepítés után alapból felkínálja a GitHub Copilot telepítését. Ez utóbbi használata ingyenes, viszont kell hozzá GitHub fiók. Ez közvetlenül a saját modelljét alkalmazza.
- Olyan kiegészítő feltelepítése, ami összekapcsolja az integrált fejlesztőkörnyezetet a modellekkel. Tehát ez esetben nincs alapértelmezett modell, hanem a beállításokban lehet kiválasztani azt. A modell maga lehet ingyenes vagy fizetős. Ilyen kiegészítő a Cline és a Continue.
- Olyan integrált fejlesztőkörnyezet használata, ami eleve tartalmazza az MI kiegészítéségeket. Ilyen pl. a Cursor és a Void.
A Continue az egyszerűbb, ennek viszont megvan az az előnye, hogy egyszerűbb, akár saját gépen futtatható modellel is működik. Erről majd később lesz szó részletesebben.
Az írás pillanatában a legfejlettebb kombináció ez: Visual Studio Code + Cline. Ehhez tehát a Cline kiegészítőt kell feltelepíteni. Néhány érdekesség:
- Két módot használ: tervezés (Plan) és cselekvés (Act). Praktikus először megterveztetni az alkalmazást, és csak utána hagyni megvalósítani. A tervezés során kérdéseket tesz fel, amire válaszolnunk kell (pl. feldob lehetőségeket, és az egyiket ki kell választani). Utána elég az Act-et kiválasztani, és megvalósítja.
- Nincs alapértelmezett modellje. Számos ingyenes és fizetős modellt kínál, sőt, további API szolgáltatókat is ki tudunk választani, és azok modelljei közül választhatunk. Az API kulcsokról később lesz szó részletesen.
- A fejlett lehetőségek, pl. külön Plan és Act lehetőségei miatt az egyszerűbb modellekkel nem működik. Pl. nem tudunk olyan modellt indítani egy 16 GB RAM-mal rendelkező számítógéppel, ami megfelelő lenne a CLine-nak.
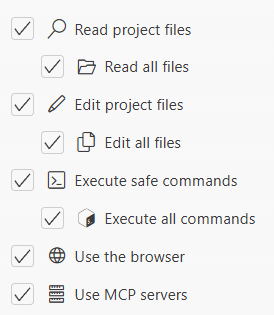
- Az alábbi képernyőkép az automatikus jóváhagyásokkal kapcsolatban készült. Ebből láthatjuk a lehetőségeket is: fájlok olvasása és írása, parancsok futtatása, böngésző és MCP szerver használata. Az ingyenes modellek nem tudják használni a böngészőt.
Parancssori alkalmazások
Ezeket parancssorból indítjuk. Létjogosultságok akkor volt a legjelentősebb, amikor az IDE MI kiterjesztések még a kódkiegészítésre és az éppen megnyitott forráskód szerkesztésére korlátozódtak, míg a parancssori alkalmazások látták a teljes fájlrendszert, parancsot tudtak végrehajtani stb. Mára ez a különbség elhalványult, sőt, el is tűnt, ill. a beépített böngészővel az IDE beépülők már előnyben vannak a parancssori alkalmazásokkal szemben. Ugyanakkor a tapasztalatok szerint továbbra is van létjogosultsága a parancssori alkalmazásnak az IDE beépülővel szemben:
- Általában kevesebb pénzt fogyasztanak, olcsóbbak. Célzottabban választanak feladathoz modellt.
- Sokkal “bátrabbak” a parancsok futtatásában, valamint nagyobb mennyiségű fájl módosításában, így bizonyos feladattípusoknál hatékonyabban. A parancsok és scriptek futtatása ezek számára természetes, az IDE beépülők “ezt is tudják”, de nem ez a fő tudásuk.
Hátrányaik:
- Korlátozott a vizuális visszajelzés. Míg az IDE beépülők kihasználják az IDE által nyújtott vizuális elemeket a változtatások kiemelésére, a parancssori alkalmazások esetleg diff formátumban jelenítik meg, amihez vissza kell görgetni.
- Nem látják az eredményt, nincs beépített böngészőjük.
Példák:
- Claude: az Anthropic vállalat terméke, ami csak a saját modelljeit támogatja, pl. Claude Sonnet.
- Aider: egy CLI felület a különböző modellekhez. Nincs alapértelmezett modellje, viszont bármelyik használható megfelelő API kulcs birtokában. Mélyen integrálódik a Git verziókövetővel.
- Continue: szintén egy CLI felület különböző modellekhez.
Autonóm platformok
A fenti lehetőségekben a lehetőségek egyben a korlátok is. Azt még megengedjük, hogy módosítsa a projektfájlokat, esetleg bizonyos parancsok futtatását, de ez utóbbit nagyobb mennyiség esetén nehéz ellenőrizni. De vajon megengedjük azt, ami tartósan módosítja a rendszerünket? Például azt, hogy letöltsön az internetről egy alkalmazást és feltelepítse? Vagy módosítson az operációs rendszer beállításain?
Az autonóm platformok ezekre a problémákra nyújtanak megoldást. Ezeknek van egy saját operációs rendszerük, és ott úgy “garázdálkodhatnak”, ahogy csak akarnak; a gazda gépre minimális a hatásuk. Például a létrehozott fájlok látszódnak a gazda gépről is egy megosztott könyvtárban, esetleg egy belül indított webszerver portját is láthatóvá tudjuk tenni, de a saját kis környezetében bátran telepíthet, módosíthat; a legrosszabb esetben letöröljük és újratelepítjük.
Az első ilyen rendszer a Devin volt, amire a fejlesztő cég először hivatkozott úgy, hogy ő az első junior fejlesztő. Sajnos ingyenes kipróbálási lehetőség nem volt, az előfizetés pedig meglehetősen drága volt (hiszen nem a magánszemélyeket, hanem a vállalati szektort célozták meg ezzel), így független eredményeket nem ismerek.
Ennek ingyenes alternatívája az OpenHands. Ez Docker segítségével fut. A beállítása tehát amiatt nem triviális, mert a Docker feltelepítése nem az: engedélyezni kell a virtualizációt (operációs rendszer, de akár BIOS szintjén); sem a Docker, sem a Docker alkalmazás telepítése nem egy egyszerű Next → Next → Finish.
Ha sikerül feltelepíteni, akkor böngészőből tudjuk megnyitni a felületet. Látunk egy chat ablakot, valamint azt, hogy van neki integrált fejlesztőkörnyezete, Jupyter notebook-ja és böngészője. Tud egeret és billentyűzetet használni. Ráadásul a böngészővel az internetes oldalakat is meg tudja nyitni, így lehet például olyat kérni, hogy “nézd meg ennek és ennek a Python csomagnak a legfrissebb változatát, telepítsd fel, valósítsd meg ezt meg ezt stb.”
Hátrányuk az autonóm platformoknak, hogy igazán jól csak fizetős modellekkel működnek.
Noha az autonóm platformok ígéretesek, a nehézkes telepítés és használat, a gyakran tapasztalt problémák és az IDE beépülők jelentős fejlődése és a határ elmosódása egyelőre akadálya a széleskörű elterjedésének.
Modellek
Tulajdonságok és árazás
Számos nagy nyelvi modell létezik. A legfontosabb tulajdonságaik a következők:
- Méret. Ne felejtsük: a nagy nyelvi modellek a mély tanulás eredményei, neuron hálók, amelyek neuronrétegekből és közöttük levő kapcsolatokból állnak. Az igazán nagy méret itt nem a neuronok száma, hanem a neuron kapcsolatok száma. Egy modell méretét a paraméterek, tehát a kapcsolatok számában adják meg, melynek nagyságrendje a milliárd. A legkisebb modellek 1 alattiak, a legnagyobbak több száz milliárd nagyságrendűek. A fájlméret durván a paraméter méret 0,6-szorosa. A futtatásához a teljes modell el kell, hogy férjen a memóriában, és ez az egy adott számítógépen futtatható modellek legfontosabb korlátozó tényezője.
- Tokenek száma. Egyetlen modell sem tud végtelen bemenetet elfogadni és végtelen eredményt produkálni. Nagyon távolról és nagyon hunyorítva felfoghatjuk a tokent úgy is, mint szót, de technikailag ez inkább 4 karakter. Angol nyelven 1000 token nagyjából 750 szónak felel meg, magyarul olyan 400-500-nak. Háromféle token limit van: input token (legfeljebb ekkora lehet mindennel együtt a prompt), output token (legfeljebb ekkora lehet az eredmény) és kontextus (a teljes beszélgetésnek a modell által látott része legfeljebb ekkora lehet).
- A tudás jellege. Szinte mindegyik modell mindenhez ért kisebb-nagyobb mértékben, viszont vannak tulajdonságok, amelyek inkább jellemzőek egy adott modellre. Vannak kifejezetten kódoló modellek, amelyek jobban kódolnak, mint a velük együtt megjelentetett nem kódoló modellek. Egy modell lehet érvelő, ami azt jelenti, hogy először megtervezi a választ, többször is végiggondolja, és utána válaszol, szemben az egyből válaszoló modellekkel. Nem mindegyik modell tud képet, hangot vagy videót generálni.
- Zártság. Egy modell lehet nyílt (letölthető) vagy zárt (csak szolgáltatásként megvásárolható). Ennek akkor van jelentősége, ha egy vállalat adatbiztonsági okokból nem engedélyezi a felhő alapú szolgáltatás használatát, a saját szervereken történő modell futtatást viszont igen.
Egy modell használatakor tipikusan a következőkért kell fizetni:
- Input token: ez az, amit a felhasználó ad a modellnek. Ez olcsó, viszont azt is figyelembe kell venni, hogy az állapotmentes modellek esetén mindig át kell adni a teljes beszélgetést, tehát egy idő után sokba kerülhet.
- Output token: ez az eredmény. Mivel ez fogyaszt sok processzoridőt, ez jóval drágább mint az input token.
- Cache: lehetőségünk van a beszélgetés során felépített modellt (tehát magát a kialakult neuronhálózatot) gyorsítótárazni, aminek a költsége jóval kisebb, mint amennyibe a teljes addigi beszélgetés került.
Az alábbiakban átnézzük a legjelentősebb gyártókat és azok fontosabb modelljeit. Konkrét verziókat ill. számokat nem írok, mert azok gyorsan változnak.
OpenAI
A ChatGPT volt az első publikusan elérhető nagy nyelvi modell, ami 2022. november 30-án jelent meg. Ez az OpenAI terméke, és sokan azóta is ezzel azonosítják a nagy nyelvi modelleket, sőt, magát a teljes mesterséges intelligenciát. Nemcsak ez az egy nagy nyelvi modell létezik, és a mesterséges intelligencia nemcsak a nagy nyelvi modelleket jelenti.
A tisztelet megadása is arra kötelez bennünket, hogy ezzel kezdjük, valamint az is, hogy sok esetben piacvezető. Kezdetben egy modelljük volt, a specializálódás viszont már jelentős.
API kódot a következő oldalon generálhatunk: https://platform.openai.com/api-keys
Ezeket a modelleket a nagy kontextus ablak jellemzi. A legkisebbtől a legnagyobb olyan fantázianeveket adnak nekik, mint Nano, Flash, Pro és Ultra, valamint a nyílt Gemma.
Ezen az oldalon generálhatunk ingyenes tokeneket: https://aistudio.google.com/api-keys. Bizonyos korlátok vannak ugyan benne (tokenek és kérések száma egységnyi időközönként), de kipróbálásra ill. kisebb hobbi célra jól használható.
Anthropic
Ezt tartják a legjobb kódolónak. A termék a Claude, a modelleket pedig költészeti szavakról nevezték el (növekvő sorrendben) Haiku, Sonnet és Opus. Kifejezetten drága és az API-n keresztüli modellnek nincs ingyenes kipróbálási lehetőség (a chat-et ingyen használhatjuk). Ha kódoláshoz a legjobb modellt keressük, és van rá keret, de azért pazarolni sem szeretnénk, akkor a Claude Sonnet a legjobb döntés.
API kódot itt tudunk generálni (és kifizetni): https://platform.claude.com/settings/keys.
Mistral
Ez európai fejlesztésű modell. Ingyenesen elérhető; nagyjából az egyik legjobb ingyenes. Az olyan modellek, mint pl. a Cline nem kérnek kulcsot, de ha mégis szükséges, a https://console.mistral.ai/api-keys/ oldalon generálhatunk.
DeepSeek
Az első kínai modell, aminek a tudása közel van a nagy amerikai modellekhez, különösen kódolásban. Óriási előnye az ár, ami töredéke a versenytársainak. Hátránya, hogy az PI kulcsnak nincs ingyenes kipróbálási lehetősége.
Itt tudunk API kulcsot generálni: https://platform.deepseek.com/api_keys.
Alibaba
Másik kínai modell, melynek neve Kwen. Ez is olcsó, ráadásul van ingyenes változata; hátránya, hogy API kulcsot nem egyszerű generáltatni, mert kell hozzá Alibaba Cloud Model Studio. De van rá egyszerűbb megoldás, ld. később.
Ollama
Ez nem külön modell, hanem külön lehetőség. A Llama a Meta (tehát Facebook) modellje. Az Ollama egy olyan alkalmazás, ami leginkább a Dockerre hasonlít, és a segítségével modelleket lehet letölteni és futtatni saját gépen. A letölthető modelleket itt találjuk: https://ollama.com/search. Ha sikerült letölteni és elindítani, akkor az olyan eszközöknek, mint a Cline, a Continue vagy az Aider, API kulcs helyett URL-t kell megadni, ami lokálisan ez: http://localhost:11434/.
Open Router
Ez egy közös felületet biztosít az legtöbb modellhez. Tehát itt egyszer fizetünk, és használat közben választunk modellt. API kulcsot a https://openrouter.ai/settings/keys oldalon generálhatunk.
Felhasználási módok
Kódolás
Kódgenerálás
Az MI legegyszerűbb felhasználási módja a programozásban a kódgenerálás. Egyszerűbb példa:
“Valósítsd meg a prímellenőrzést Pythonban. Írj egységteszteket.”
De ennél összetettebb feladattal is megbirkózik:
“Valósítsd meg HTML-ben a PacMan játékot. A felület kinézete legyen modern.”
Kódmagyarázat
Létező kódot lehet elmagyarázatatni a segítségével.
“Értelmezd a data_generator.cpp forrásfájlt. Magyarázd el a lényegét.”
Nyelvi fordítás
Egyik programozási nyelvről a másikra tudunk a segítségével fordítani.
“A convert_data.py forrásfájlban található logikát valósítsd meg a következő nyelveken: C++, Java, C# és JavaScript.”
Kód feljavítása
Ez alatt kód refaktorálást értünk.
“Módosítsd a data_generator.py forrást úgy, hogy megfeleljen a PEP 8 ajánlásainak.”
Tesztelés
Egységtesztek írása
Az MI kiválóan alkalmas egységtesztek (unit test) generálásra és magas lefedettségi arány legedérésre.
“Írj egységteszteket a data_generator.py fájlhoz. A lefedettség a függvények értelme és ne pusztán technikai értelemben legyen magas.”
Mock adatok létrehozása teszteléshez
A tesztelést folytatva, teszt adatokat is létre tudunk hozni a segítségével.
“A sales_data HTTP API végpont teszteléséhez hozz létre különféle mock adatokat, aminek segítségével a frontenden ellenőrizni tudjuk a lehetőségeket.
Hibakeresés
Ha kapunk egy hibaüzenetet, akkor bemásolhatjuk a chat ablakba, és megkérhejtük, hogy elemezze és javítsa ki.
Fejlesztési folyamat
CLI parancsok paraméterezése
Az MI kiválóan ismeri a terminál alkalmazásokat. Példa:
“A customer.txt fájlban | jellel vannak elválasztva az adatmezők. A nyolcadik mező a telefonszám. Hozz létre egy olyan awk parancsot, mi kigyűjti a telefonszámokat.”
Ismert GUI és webes alkalmazások beállítása és használata
A gyakran használt lokálisan futtatott és webes alkalmazásokat is ismeri, azokról is kérhetünk segítséget.
“Fel szeretném telepíteni lokálisan a Jenkinst és be szeretnék állítani egy Python projektet. Adj lépésről lépésre leírást a letöltéstől a telepítésen át a beállításig.”
Vagy:
“Egy Flask webalkalmazást szeretnék beüzemelni Google Cloudban. Adj egy lépésről lépésre leírást onnan, hogy be vagyok jelentkezve a rendszerbe.”
Biztonsági audit
A nyilvánvaló biztonsági hibákat (pl. SQL injection stb.) észreveszi.
“A webalkalmazáson hajts végre egy biztonsági auditot. Nézd meg, hogy maradt-e benne nyilvánvaló biztonsági rés.”
Ötletelés
“Milyen dokumentum típusok keletkeznek a szoftverfejlesztés során? Példák: felhasználói követelmények, interfész specifikáció, telepítési dokumentáció, felhasználói kézikönyv.”
Specifikáció készítése
“Egy olyan webalalkalmazást szeretnék készíteni, ami egy iskola diákjait, tanárait, osztályait és tantermeit kezeli. Készíts egy specifikáció vázlatot, amit majd alábontunk.”
Dokumentáció generálása
“Generálj a függvényekhez fejléc dokumentációt.”
További technológiák
SQL parancsok
Egy igen gyakori felhasználási módja az MI-nek a programozásban.
“Valósítsd meg egy olyan SQL lekérdezést, ami megfelelően összekapcsolja a korábban ismertetett táblákat, és tantárgyanként kiszámolja az osztályátlagot.”
Reguláris kifejezések
Az első felhasználások egyike. Reguláris kifejezés írása nehézkes és viszonylag ritkán van rá szükség.
“Készíts egy olyan reguláris kifejezést, ami a könyvek ISBN számára illeszkedik”
CSS stílus létrehozása
Egy nem kifejezetten frontend fejlesztő számára a CSS stílus nehézkes lehet.
“Módosítsd a weboldal CSS-ét úgy, hogy annak kinézete juicy legyen.”
CRON időzítés létrehozása
Erre is ritkán van szükség, és egyszerűbb megkérdezni, mint akár megjegyezni, akár utána járni.
“Készíts egy olyan CRON időzítés bejegyzés, amivel minden nap 14:45-kor futtatjuk a scriptek.”
Git utasítások generálása
A Git alapjait gyakran használjuk, de vannak esetek, amikor “eltévedünk az ismeretlen, sűrű erdőben”.
“Úgy látom, félrement nálam lokálisan a Git távoli repository. Segíts kibogozni a szálakat!”
Shell scriptek generálása
A programozási nyelvek mellett shell scriptekben is kiválóan teljesít az MI.
“Késztíts egy olyan scriptet, ami a customer.txt fájlból kiolvassa a második és a nyolcadik elemet (elválasztó: pipe), és belehelyezi a phone_numbers.txt fájlba. A második a név, a nyolcadik a telefonszám. Ha már benne van a fájlba, akkor ne tegye bele újra.”
Elmélet
Adott algoritmus vagy adatszerkezet elmagyarázása
Elméleti kérdésekben az MI verhetetlen.
“Magyarázd el a Dijkstra algoritmust.”
“Foglald össze a piros-feket fák lényegét.”
Futásidő elemzés
“Mennyi az ordó jelöléssel kifejezett futásideje a find_order_by_customer függvénynek?”
Kérdés a számítástudomány tetszőleges területén
“Magyarázd el a szimplex algoritmust egy egyszerű példán keresztül.”
“Hogyan működik az SVM gépi tanuló algoritmus?”
“Milyen elemei vannak a Chomsky-hierarchiának?”
További lehetőségek
Az alábbiakat csak bizonyos körülmények között (felhasználási módok, modell) tudjuk alkalmazni.
Futtatás és elemzés
Ehhez kell terminál, ahol le tudja futtatni. A chat ablakban ez általában nem áll rendelkezésre.
“Futtasd le az egységteszteket, és javítsd ki a talált hibákat. Javítás után ismét futtasd le, és mindaddig ismétled, amíg mindegyik hiba ki nem lett javítva.”
Látás
Nem “lát” mindegyik modell, és csak bizonyos módszereknél elérhető.
“Nyisd meg az table.html oldalt. A táblázat eleme szét vannak csúszva. Módosítsd a CSS-t úgy, hogy ezt a hibát megjavítsa.”
“A könyvtárban van 6 html fájl, mindegyik egy játékot tartalmaz. Az indításhoz mindegyik esetben a játékosnak rá kell kattintania a Start gombra. MIndegyik játékról készíts úgy képernyőképet png formában, ami pont akkor látszódik, amikor a felhasználó rákattintott a Start gombra.”
Lehetőségek
A közeljövő fejlesztője
Talán már lehet azt is mondani, hogy a jelen fejlesztője a következőképpen néz ki:
- Context engineering: a prompt engineering továbbgondolása. A prompt engineering már ma alapvető készségnek számít: amilyen természetességgel kerestünk a neten a Google segítségével, olyan természetességgel kell tudni egy fejlesztőnek használni egy chatbotot. Viszont nemcsak az a fontos, hogy milyen promptot írunk, hanem hogy mit adunk a kezébe: melyik fájlokat, milyen dokumentációt, milyen példát. Ez az új programozói skill: az AI “etetése” a megfelelő információval.
- Kód értés: mivel a kódot alapvetően az MI fogja generálni és nem az ember írni, a kódolvasási készség szerepe felértékelődik.
- Szintaxis tudás leértékelődése: egy adott nyelv vagy technológia szintaxisának az ismerete önmagában értéktelenné válik. A szintaxist továbbra is ismerni kell, de önmagában nem lesz elég (bár önmagában eddig sem volt elég), mert az MI tökéletesen ismeri a szintaxist.
- Minőségbiztosítás: a jövő fejlesztőjének nem a szintaxissal kell foglalkoznia, hanem az MI által generált kód minőségének a biztosításával: annak átnézésével, validálásával és szükség esetén javításával. Ez egyébként sokszor nehezebb, mint maga a kódírás.
Középtávú fejlődési lehetőségek
A tendekből néhány középtávú (hónapok-évek) fejlődési irány kirajzolódik:
- A modelleket egyre több adattal tanítják. Hamarosan megközelíti a tanító adatmennyiség mindazt, amit ember valaha digitalizált, azaz nem lesz túlzás állítani, hogy benne lesz az emberiség össztudása. Az új adat keletkezése viszont nem tartja a tempót a felhasználással (különösen úgy, hogy az MI gyakorlatilag “kinyírta” az internetet: sok esetben nem rákeresünk, hanem modellt kérdezünk, ráadásul a Google is sokszor összefoglalja a választ, tehát a tartalomkészítőknél nem keletkezik forgalom, nem lesz reklámbevétel, így olyan sok új tartalom sem keletkezik), ezáltal hamarosan beleütközünk az adatfalba.
- A paraméterek számát (neuronok, rétegek, ezáltal kapcsolatok száma) is lehet növelni, bár a végtelenségig azt sem éri meg, mert nem feltétlenül ad annyit hozzá, hogy az eredmény érdemben jobb legyen, különösen azután, hogy beleütköztünk az adatfalba.
- A tokenek száma (kontextus, input, output) növekszik, és minél nagyobb a kontextusablak, annál nagyobb kódbázist tud átlátni a modell.
- Kisebb-nagyobb ötletek addig is voltak és ezután is lesznek minden bizonnyal. Korábbi ötletek: Plan-Act mód, belső böngésző indítása stb. Egy saját ötlet: debugger használata (a böngésző mintájára).
Hosszú távú fejlődési lehetőségek
A jelenlegi tendenciák hamarosan falakba ütköznek. Ahhoz, hogy új lökeket adjunk a mesterséges intelligencia fejlődésének, és exponenciális pályán tartsuk, újabb olyan szintű ötletekre van szükség, mint volt például a mélytanulás megjelenése a gépi tanuló algoritmusok között.
Korlátok
Vannak olyan korlátok (pl. hallucináció, kontextus limit stb.), amelyek már ma sem jelentenek megoldhatatlan problémát, és várhatóan a jövőben még kevésbé jelentkeznek. Arra tehát nem lehet “építeni”, hogy az MI-t amiatt nem fogják használni a fejlesztők, mert egyszer valakinél egy nem létező függvényt próbált meghívni, tehát fejlesztőre mindig szükség lesz.
A junior paradoxon
A mesterséges intelligencia hatása a munkaerőpiacra kétségkívül jelentős. Ugyanannyi munka elvégzéséhez kevesebb fejlesztő is elegendő, és elsősorban a junior fejlesztők azok, akik ennek a legnagyobb elszenvedői. De ha a cégeknek senior fejlesztőkre van szükségük, és nem vesznek fel juniorokat (mivel az MI tökéletes junior, sőt, medior), akkor a juniorok hogyan szereznek tapasztalatot és válnak seniorokká?
A kérdésre nehéz a válasz, egyelőre nem tudjuk. Annyi biztos, hogy a junior fejlesztők szerepe is átalakul íróból olvasóvá. A múltban a junior írta a “favágó” kódot, amit a senior átnézett. A jövőben vélhetően az MI írja a kódot, és a juniornak kell átnéznie.
A másik paradoxon ezzel kapcsolatban az, hogy hogyan tanul meg valaki hibát keresni (olvasni), ha sosem írt eleget ahhoz, hogy elkövesse ezeket a hibákat? Ez a szakma legnagyobb kihívása jelenleg. A junioroknak sokkal hamarabb kell rendszertervező fejjel gondolkodniuk, mint régen.
A junior fejlesztők nem tűnnek el, de a belépési küszöb megváltozik: a szintaxis magolása helyett a kódolvasás, a hibakeresés és a rendszerszemlélet válik az elsődleges junior készséggé. Aki csak kódolni tud, de ellenőrizni nem, azt az MI kiváltja.
Az emberi megértés hiánya
A kódbázis egyre nagyobb hányada lesz olyan, hogy ember azt valódi mélységében nem értette meg soha. Az igazán mély megértés tipikus következménye a javítás, és ez esetben az is bekövetkezhet, hogy az MI segítségével megírt kód fejlesztése bruttó időben végül hosszabb ideig tartott, mintha tisztán ember írta volna. Az idő előrehaladtával ez a probléma várhatóan egyre nagyobb lesz, és még nem látszik kirajzolódni a megoldás.
Nem determinizmus
Az a tény, hogy a generált kód nem determinisztikus olyan értelemben, ahogy például egy fordítóprogram elkészíti a gépi utasításokat a forráskódból, hosszú távon is tartós probléma marad. Nem fér kétség ahhoz, hogy a “készíts egy modern stílusú Tetrisz webalkalmazást” parancsot egyre jobban meg fogja tudni oldani, csakhogy ennek a feladatnak nem egyetlen megoldása van, hanem végtelen sok. Ezáltal akármilyen fejlett is a mesterséges intelligencia, törvényszerűen eljön az a pont, amikor a nemdeterminizmus nem elfogadható, azaz rá kell nézni a kódra. Arra persze számíthatunk, hogy az idő előrehaladtával egyre nagyobb kódbázis generálását bízhatjuk rá, valamint arra is, hogy az utasításainkat egyre pontosabban teljesíti, de azzal, hogy a folyamat nem determinisztikus, törvényszerűen el kell jönnie annak a pontnak, amikor egyszerűbb a kódot nekünk módosítani, mint promptokkal utasítani, majd újabb promptokkal megkérni a hibák javítására.
És hol tartunk most ebben a folyamatban? Egy-két éve még azt írtam volna, hogy kb. 100 sor kód alatt tekinthető stabilnak a mesterséges intelligencia által generált kód, és néhány (5 alatti) promptig még érdemes próbálkozni, de utána célszerű átvenni a fejlesztést. Az írás pillanatában (2026 eleje) a tapasztalatom szerint határ valahol 1000 és 2000 sor kód között van, amit pár tucat prompttal lehet elérni. Jelenleg ez az a méret, aminél már inkább érdemes kézzel módosítani a kódot, mint a mesterséges intelligenciára bízni.
A mesterséges intelligencia eszközök egyre jobbak, és ennek következtében valószínűleg egyre kevesebb fejlesztőre lesz szükség ugyanannyi munka elvégzéséhez, ugyanakkor a nem determinizmus miatt azt gondolom, hogy az ember nélküli, teljesen automatizált fejlesztést nem fogja elérni a mesterséges intelligencia, különösen nem a közeljövőben.


